DeepSeek-V4全新上线!价格表出来了!
2026/4/24 
4月24日,DeepSeek全新系列模型DeepSeek-V4的预览版本正式上线并同步开源。据介绍,DeepSeek-V4拥有百万字超长上下文,在Agent能力、世界知识和推理性能上均实现国内与开源领域的领先。API服务已同步更新,通过修改model_name为deepseek-v4-pro或deepseek-v4-flash即可调用。
据悉,受限于高端算力,目前DeepSeek-V4-Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。
大模型领域再次迎来重磅更新。国产 AI 领军者 DeepSeek 今日正式发布了其新一代旗舰模型DeepSeek V4。本次发布最大的亮点在于模型的细分化策略,通过Flash与Pro两个版本,精准覆盖了从高频轻量化应用到复杂推理任务的不同需求,并再次以极具竞争力的价格重塑了 AI 商业化定价基准。
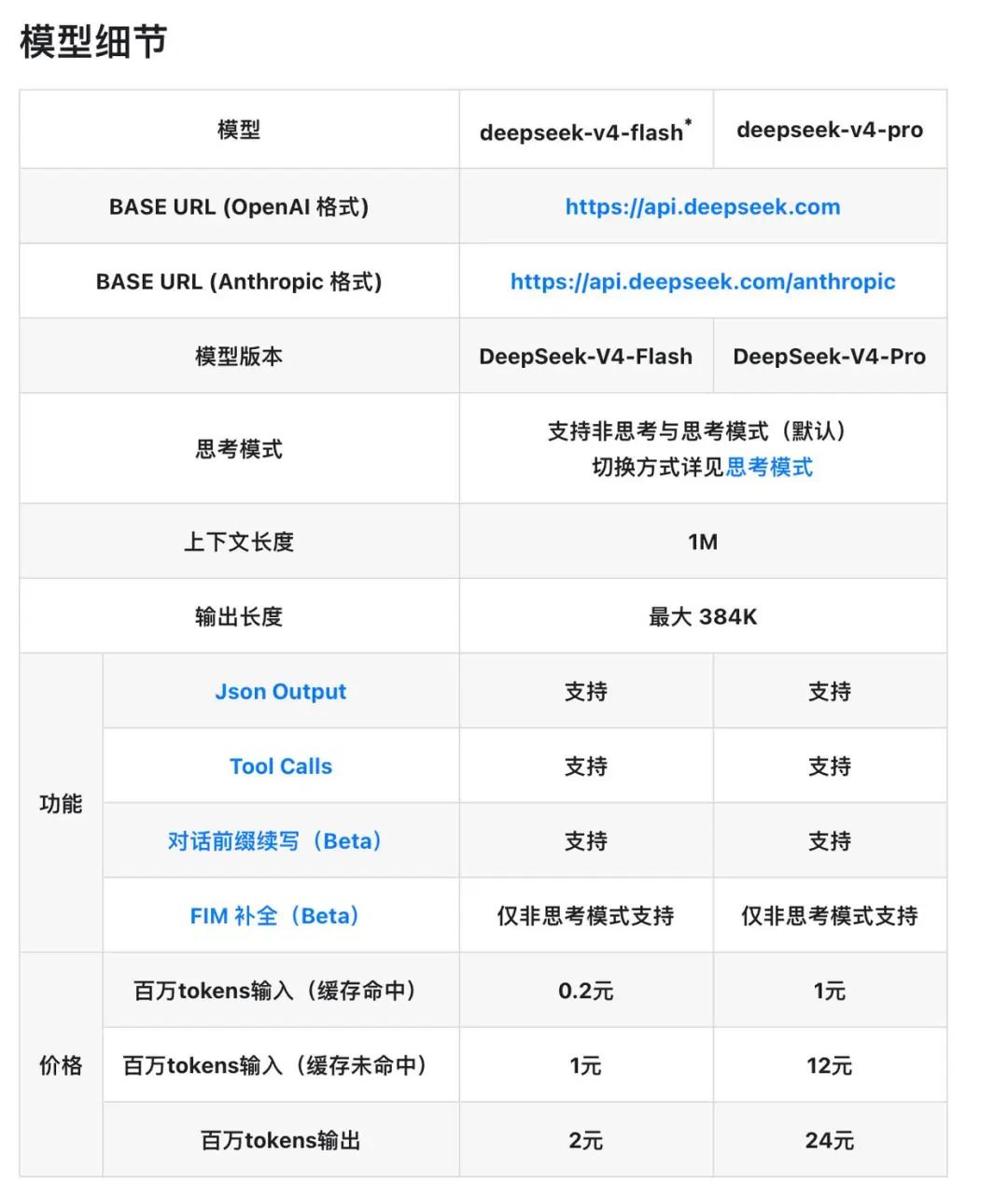
模型矩阵:Flash 与 Pro 的差异化定位
DeepSeek V4将原有的deepseek-chat与deepseek-reasoner模型进行了整合与升级,正式划分为两个版本:
DeepSeek-V4-Flash:主打极致性价比与高吞吐效率,适合需要快速响应的通用对话及基础文本任务。
DeepSeek-V4-Pro:针对复杂逻辑、深度思考任务及高性能算力场景进行优化,具备更强的推理与处理能力。
两款模型均支持思考模式(除特定场景外)、Json 输出、Tool Calls 以及对话前缀续写(Beta),并支持高达1M 的上下文窗口与最大384K 的输出长度,为复杂工程落地提供了坚实基础。
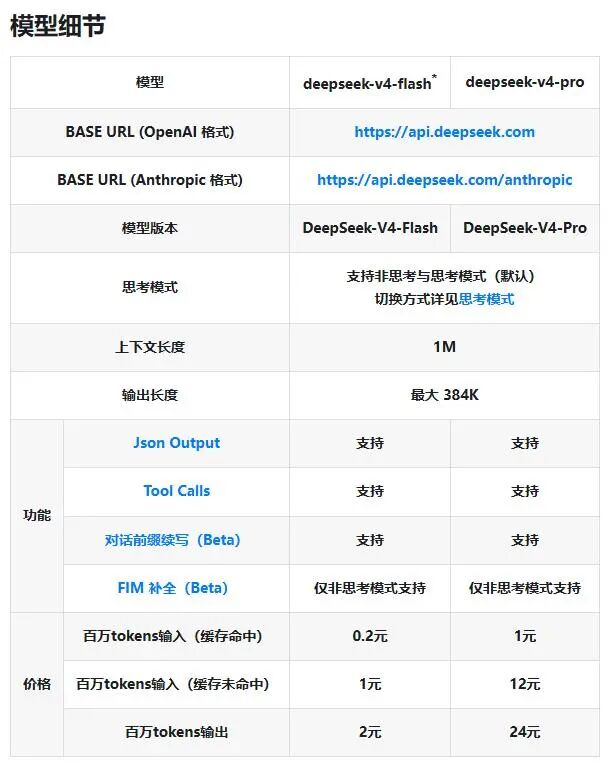
价格体系:极致透明,阶梯化计费
此次 DeepSeek 公布的定价逻辑清晰,通过缓存机制大幅降低了企业长期调用的边际成本。以下为各模型的具体计费标准(单位:元/百万 Tokens):
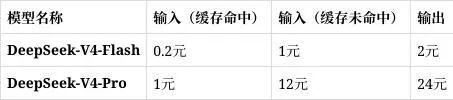
注:扣费优先使用赠送余额,随后从充值余额中抵扣。
行业分析:为何这一价格具有里程碑意义?
从定价逻辑可以看出,DeepSeek 正在通过“缓存命中”与“未命中”的显著价格差,鼓励开发者通过缓存优化来降低算力损耗,从而实现业务成本的精细化控制。
对于开发者而言,Flash 版本1元/百万 Token(缓存未命中)的价格,极大地降低了接入顶尖 MoE 模型架构的准入门槛。同时,Pro 版本针对复杂推理任务的定价,也为企业构建知识库问答、自动化代理(Agent)等高阶应用提供了兼顾性能与成本的国产方案。
关于兼容性的重要提示
官方特别提醒:原有的deepseek-chat与deepseek-reasoner模型名将于后续正式弃用。为了保障业务平稳过渡,开发者现已可直接调用deepseek-v4-flash(对应非思考模式)与deepseek-v4-pro(对应思考模式)。
有关模型详细接口信息及迁移指南,开发者可访问DeepSeek API 官方文档进行查看。
更多AIE展会资讯
请关注“AIE全球智能制造与电子博览会”
